Somewhere in your organization right now, an AI agent may be running on a shared service account with no identity controls, no content boundaries, and no audit trail. It was probably deployed fast, with good intentions, and no one asked the most important question: what happens when it does something wrong?
That is the enterprise AI problem in one sentence. And AI guardrails are the answer.
This post breaks down what AI guardrails actually are, why they are non-negotiable for regulated enterprises, and how Ejento builds them into every agent deployment by default — so your teams can move fast without creating risk they cannot see.
What are AI guardrails?
AI guardrails are the rules, validation layers, and policy controls that define what an AI agent is — and is not — permitted to do. They are the boundary between an AI system that is useful and one that is dangerous.
In practice, guardrails operate at several levels:
Behavioral guardrails define what an agent can say and do. They prevent agents from producing harmful, biased, or off-topic outputs. A customer service agent, for example, should never provide legal advice or discuss competitor pricing — behavioral guardrails enforce that boundary at runtime, not by hoping the model self-regulates.
Deterministic validation layers sit between an AI agent and the operational systems it interacts with. When an agent proposes an action — updating a customer record, issuing a refund, routing an approval — the validation layer checks whether that action complies with predefined rules before it executes. This is the difference between a guardrail and a suggestion.
PII and content controls ensure sensitive data never appears in agent outputs or gets written into knowledge sources without authorization. At ingestion, well-designed guardrail systems detect and redact personally identifiable information before it enters the agent’s context.
Human-in-the-loop checkpoints intercept high-stakes decisions and require human review before an agent proceeds. These are not a sign that the agent has failed — they are a designed feature that extends trust responsibly.
Prompt injection defenses treat external inputs — emails, uploaded documents, web forms — as potential attack vectors. The OWASP Top 10 for LLM Applications 2025 ranks prompt injection as the single most critical vulnerability in enterprise AI deployments. Without this class of guardrail, a malicious instruction embedded in a document can redirect an agent’s behavior in ways the deploying organization never intended.
Together, these layers form the governance structure that turns a probabilistic AI model into a trustworthy enterprise system. Without them, you do not have an AI agent. You have an autonomous process operating without accountability.
Why AI guardrails are non-negotiable for enterprises
The risk isn’t hypothetical
Most enterprise leaders still think about AI risk in terms of bad content — an agent saying something wrong. That is content risk. Agentic AI introduces execution risk: the agent does something wrong.
When an AI agent has write access to your CRM, your helpdesk, your pricing systems, or your financial workflows, a single misconfigured output can trigger a cascade of incorrect actions across systems — at machine speed, without human review, and often without a clear audit trail to reconstruct what happened.
The Air Canada ruling in 2024 established this clearly: a company cannot disclaim responsibility for its AI agent’s actions by treating the agent as a separate entity. Regulatory accountability belongs to the organization, regardless of whether the action was taken by a human or a system.
The regulatory landscape is closing in
Regulation on enterprise AI is no longer theoretical. The EU AI Act — the world’s first comprehensive legal framework for AI — has been progressively taking effect since 2024, with full enforcement of high-risk AI system obligations by August 2026. Violations of prohibited AI practices carry fines up to €40 million or 7% of global annual turnover. The Act explicitly requires human oversight mechanisms, audit documentation, and risk management systems for high-risk deployments — all of which are guardrail problems at their core.
In the United States, the NIST AI Risk Management Framework (AI RMF), updated for generative AI in 2024, has become the de facto governance standard. Federal agencies, regulated industries, and enterprise procurement teams increasingly reference the NIST AI RMF when evaluating AI vendors. Its four functions — Govern, Map, Measure, Manage — map directly to what guardrails must accomplish in production: define boundaries, identify risks, enforce controls, and continuously improve.
The four frictions that derail enterprise AI
Research identifies four structural frictions that consistently cause enterprise AI agent projects to stall or fail. Each one is a guardrail problem in disguise.
Identity. Most early deployments run agents on shared service accounts with broad system access — eliminating the role-based limits applied to human employees. Without per-agent identity and scoped credentials, there is no way to answer the most basic governance question: who took this action, and were they authorized to?
Context. Real enterprise data is fragmented, outdated, and often contradictory. An agent that retrieves an expired policy document and acts on it has not hallucinated — it has made a retrieval error. External inputs like emails and forms can also be weaponized through prompt injection to manipulate agent behavior. Guardrails at the context layer prevent both failure modes.
Control. Large language models are probabilistic. The same input can produce different outputs across runs. In a multi-agent environment, a control failure at one step cascades to every downstream step. Deterministic validation layers are the only reliable way to enforce compliance before execution occurs. The OWASP LLM Top 10 2025 flags “Excessive Agency” — agents with unchecked autonomy and permissions — as one of the most significantly elevated risks in agentic architectures.
Accountability. When something goes wrong — and in production at scale, something eventually will — you need to reconstruct exactly what the agent did, which data it relied on, and why it made the decision it made. Without immutable audit logs and reasoning chain reconstruction, that question cannot be answered. For regulated industries, that is not an inconvenience. It is a compliance failure.
The regulatory trajectory only goes one way
Financial services regulators, healthcare compliance bodies, and federal agencies are all moving in the same direction: organizations are responsible for the actions of their AI systems, and they must be able to prove it. Deploying AI agents without enterprise-grade guardrails is not a calculated risk — it is a future liability that has not materialized yet.
Guardrails are not a feature you add when a regulator asks. They are the infrastructure you build before you deploy.
How Ejento helps enterprises deploy AI agents with proper guardrails
Ejento is built on a single founding conviction: an AI agent should be governed exactly like a new team member. That means a defined role, a bounded scope of authority, access to the right — and only the right — information, clear escalation rules, and a complete record of every action it takes.
This philosophy — the Teammate Governance Model — is not a product positioning statement. It is the architectural default that every Ejento agent operates under from day one.
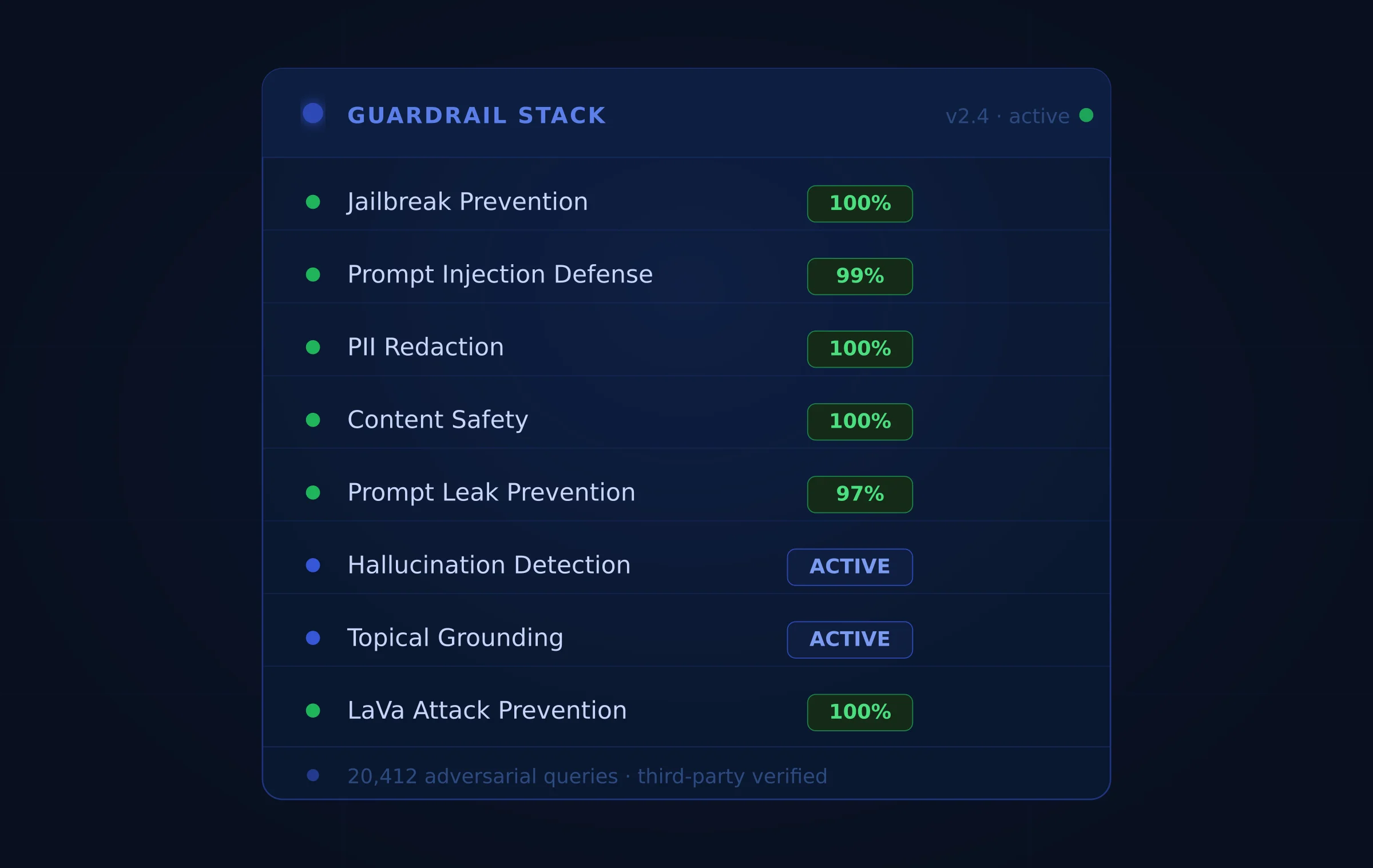
1. Eight built-in guardrail layers, on by default
Ejento ships with eight independent AI guardrail layers, all tested against 20,412 adversarial queries by a third-party independent lab. These are not optional configurations — they are on by default for every agent deployed on the platform:
- Jailbreak Prevention — 100% block rate against role override and constraint bypass attempts
- Prompt Injection Defense — 99% block rate against document, web content, and tool output injection
- PII Redaction — 100% detection and masking of names, emails, financial data, and health identifiers
- Content Safety — 100% enforcement against hate speech, harmful content, and policy violations
- Agent Prompt Leak Prevention — 97% protection against system prompt extraction attacks
- Hallucination Detection — Flags responses that deviate from grounded knowledge sources with source attribution
- Topical Grounding — Keeps agents on-topic and within their authorized knowledge scope
- LaVa Attack Prevention — 100% defense against multimodal adversarial inputs combining text and visual content
Every one of these aligns with the OWASP Top 10 for LLM Applications 2025 vulnerability framework, covering the attack vectors enterprises face most in production. The block rates come from real third-party penetration testing — not internal benchmarks.
2. Per-agent identity and role-based access control
Every Ejento agent receives its own distinct digital identity and a role-scoped set of credentials. There are no shared service accounts. Each agent can only access the systems, connectors, and data sources its specific role requires — the same least-privilege principle applied to human employees.
RBAC is enforced at six layers: organization, team, project, agent, knowledge source, and individual tool or MCP connector. This means that even if an agent is compromised through a prompt injection attack, its blast radius is bounded by what it was authorized to do — not by everything the platform has access to.
This architecture also makes autonomy expansion safe and reversible. As an agent demonstrates reliable behavior within its current permissions, those permissions can be widened incrementally. If a problem is detected, they can be narrowed immediately — without rebuilding the agent or affecting other deployed systems.
3. Governed knowledge sources and context protection
The context layer is where most enterprise AI deployments fail quietly. Ejento resolves this at ingestion, not after the fact.
PII detection and redaction run automatically as documents enter the knowledge base. Document Verification flags potentially outdated content for human review before agents are permitted to rely on it. External inputs — emails, forms, uploaded files — are validated as potential attack vectors before they influence agent behavior, closing the prompt injection attack surface that most platforms leave open.
Every agent decision records context provenance: which documents it accessed, which data sources it queried, and which retrieved content it based its response on. This supports the evidence layer that makes accountability reconstructable — exactly what the EU AI Act’s technical documentation requirements demand.
4. Immutable audit logs and full accountability infrastructure
Ejento maintains comprehensive, immutable audit logs of every agent interaction: which knowledge sources were accessed, which tools were invoked, what instructions were followed, and what action was taken or proposed.
These logs answer the question regulators and auditors actually ask: why did the agent do that, and can you prove it was authorized? The reasoning chain behind any agent decision can be reconstructed from the audit record, with source attribution, tool call history, and identity provenance intact.
Ejento’s audit infrastructure is SOC 2 Type II compliant and supports SIEM export for integration with existing security operations workflows.
5. Red teaming and continuous evaluation
Guardrails set at deployment are a starting point, not a finish line. Ejento’s native evaluation suite and red teaming capabilities let organizations stress-test their agents before and after deployment — without requiring a separate tool.
The red teaming module covers 30+ probe categories aligned to the OWASP LLM Top 10, with converters, scorers, and exportable vulnerability reports. Evaluation runs can be built from real query history or custom datasets, and include metrics covering answer correctness, context recall, faithfulness, and a 10-category ethics and safety scoring framework.
This approach aligns with the NIST AI RMF’s guidance that AI risk management must be treated as a continuous improvement cycle — not a one-time compliance checkbox before launch.
6. VPC-native deployment: guardrails that never leave your cloud
Every guardrail Ejento enforces, every audit log it maintains, every piece of data it validates runs entirely within the customer’s own cloud infrastructure on AWS, Azure, or Google Cloud. Nothing — not prompts, not documents, not agent outputs, not telemetry — crosses the VPC boundary to a shared vendor backend.
This architecture matters for guardrails specifically because the most sensitive data your agents handle is precisely the data that should never leave your cloud. When a guardrail redacts PII at ingestion or intercepts a high-stakes action for human review, that process happens in your environment, under your control, auditable by your team.
The autonomy ladder: guardrails that scale with trust
Ejento’s guardrail architecture is not designed to keep agents permanently constrained. It is designed to give organizations a clear, defensible path for expanding agent autonomy as trust is established.
The platform supports a structured progression from Level 1 (assistive output — humans review everything) through Level 4 (bounded autonomy — agents execute independently within defined thresholds, escalating automatically when limits are reached). At every level, the governance infrastructure is in place. The difference between levels is the scope of authority granted, not the presence or absence of accountability.
Guardrails are what make that expansion safe. And they are what proper AI evaluation validates before any agent reaches production.
Frequently asked questions
What is the difference between AI guardrails and AI safety?
AI safety is a broad research discipline concerned with ensuring AI systems behave in alignment with human values across all possible scenarios. AI guardrails are the practical, operational controls organizations deploy to enforce specific behavioral boundaries in production systems. Safety research informs guardrail design; guardrails are what actually runs in your enterprise environment.
Are AI guardrails required for regulatory compliance?
Increasingly, yes. The EU AI Act requires risk management systems, human oversight mechanisms, and technical documentation for high-risk AI deployments — all of which are guardrail problems. The NIST AI RMF, while voluntary in the US, is referenced in procurement requirements across regulated industries. Organizations in financial services, healthcare, and government should treat guardrails as a compliance infrastructure requirement, not a product feature.
Do AI guardrails slow down agent performance?
Properly architected guardrails add minimal latency when they run natively alongside the inference pipeline — as Ejento’s do. The performance cost of deterministic validation layers is orders of magnitude smaller than the operational cost of a guardrail failure in production.
Can guardrails prevent all AI agent failures?
No single control eliminates all risk. Layered guardrails — identity controls, prompt injection defenses, content validation, human-in-the-loop checkpoints, and continuous red teaming — reduce risk to levels that regulated enterprises can manage. The goal is not perfection. It is defensibility, auditability, and the ability to contain failures when they occur.
The bottom line
AI guardrails are not a compliance checkbox. They are the infrastructure that makes enterprise AI agents trustworthy — and trustworthy agents are the only ones that survive contact with production.
Organizations that deploy agents without guardrails are not moving faster. They are accumulating liability that has not surfaced yet.
Ejento builds the full guardrail stack — identity, context protection, deterministic control, human oversight, immutable audit trails, and continuous red teaming — into every agent deployment by default. Not as an add-on. Not as a configuration option. As the architectural foundation every enterprise-grade agent requires.
Ready to see what governed AI agents look like in your own cloud?